
This is a late and short update on the eruption in Fagradalsfjall mountain on 12-September-2021. Fagradalsfjall mountain is part of Krýsuvík-Trölladyngja volcano system.
Yesterday (11-September-2021) at around 05:00 the harmonic tremor on SIL stations around Fagradalsfjall mountain started to show an increase in harmonic tremor after a break of 8 days. It took few hours for the magma to reach the crater and lava was visible in the crater around 12:00 UTC.
There have been possible new vents been opening up yesterday and today in the lava field. Icelandic Met Office says that this is a lava flow under the old colder lava and is now breaking up and looking like new vents. I don’t know yet if this is accurate, but it is my early assessment that this are new vents and are going to build new crater, at least there is a possibly of crater building if the new vents stay active long enough.
If this are new craters as I suspect, then they are going to change the lava flow quickly and increase the output of the lava flow from what it was. It might soon start to flow down into Nátthagi and other locations that are nearby.
It is a big question if the cycle eruption with no activity for hours has stopped for now. If this has turned back into an eruption that goes in 24 hours a day, that is going to allow the lava field to reach a lot more distance then before.
Drone video showing new vent right under the north wall of crater.
https://www.youtube.com/watch?v=OSFu7Tqh4Io
In a GunTog video I watched, he said his friend felt earthquakes just before the eruption started. Small, but felt there, so these are probably new fissures that have opened as the ground opened.
Plumbing of the main vent must have collapsed, forcing the magma to find another route. RUV cam last night showed a very vigorous eruption with the new vents. Tremor plot still looks strong.
There is a possibility that a magma chamber has formed at 2 to 5 km depth. Maybe as deep as 10 km, but that is unlikely possibility. If that is what happened, it changes the dynamic of the eruption in Fagradalsfjall mountain.
This appears to be a new vent that has appeared inside the north wall. Lava is erupting both to the north into northern Geldingadalir and into the crater from the wall as seen in a recent drone video from Green Iceland Videos YouTube channel.
One scientist on Twitter speculates it is a reactivation of the second vent in the vent 5 system which went dormant after the southernmost vent became dominant.
My personal opinion is that if this continues we are at a greater likelihood of seeing the north wall developing a significant breech and failing completely.
Based on this drone vid from last night, it’s not long before the north wall is gone.
https://www.youtube.com/watch?v=oCsbaaosINo
Based on videos from during the night of 12-September-2021, before the weather started. There where several new vents in the crater (large one) and in its side close to the end of it. The new craters in the older lava field showed strong activity and I don’t think that has changed. Lava is going to go down into Nátthagi in next few hours and maybe even into Nátthagakrika (where people walked up to Geldingadalir) at the same time. The whole area is going to get flooded in next few hours by this change in the eruption.
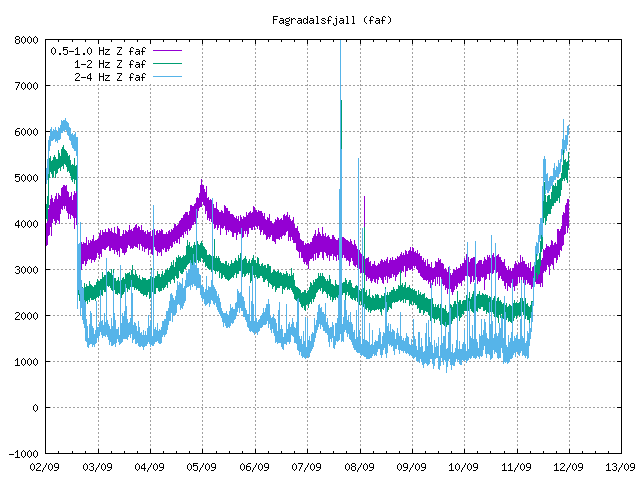
It will be interesting to see what progress is revealed when the weather improves enough for it to be seen on camera. The ‘blue’ line on the harmonic tremor graph has consistently been over 6000, so presumably the eruption continues. Does anyone know the what kind of significance relates to the purple and green ‘lines’?
The mide range and low range frequency line on the harmonic tremor tells how much force magma is pushing in the eruption. That is not a strong force based on this harmonic tremor. But this is higher than before and the eruption seems to have moved to just erupting ongoing without stopping. So far anyway.
I can’t tell about the other new craters since they are out of view. But there is one active crater on the far side viewed on the Rúv camera. The lava field doesn’t seem to allow a crater to build up for now. That might change later on.
Jón, many thanks for explaining the purple and green lines. So, is this a stronger force now than when it was erupting in the beginning, or just stronger because it is erupting again?
Tremors trending down a little, with a downward spike I see. We going back to pulse eruptions again? That’s seems to be its MO.
The tremor only seem to be trending down on higher frequencies. I am not seeing this on middle to lower frequencies. Those show the lava flow best in most situations. The eruption is ongoing and has not stopped yet. But when I write this at 18:10 there is an enormous gas cloud from the large crater and there is an ongoing lava activity on the far side of Geldingadalir (new crater?).
While the large crater erupts now in short pulses that does not happen with the activity on the far side in Geldingadalir. I am now convinced that that is a new fissure that is erupting there. Rather than being a lava flow from the crater flowing under the lava field that is there.
Hi Jón, and all. I expect none of you have risen quite this early. http://hraun.vedur.is/ja/oroi/faf.gif – this is the most unusual harmonic tremor graph I have ever seen. With the blue line descending harply into the still high purple and green lines, could this indicate some sort of blockage in the system (or a techinical fault with the live graph)?
It means erupting for a few minutes, then silent for a few minutes, then erupting again etc, you get the picture. But, due the compressed time scale, it apears like that !!
Thank you, good to know this is the stop/start eruption pattern tremor indicator!
Current cycle is 8 eruption for every 1 hour according to the news. This cycle is interesting and I am not sure what that means for now.
Just means it’s doing what it usually does. This thing just pulses on different timescales. Its name should be “Pulsar”. What’s that in Icelandic? 🙂
I wonder if this behavior is common in the under sea eruptions along the mid Atlantic ridge? We don’t have any good info on that, I’m sure. Pretty difficult to monitor.
Volcanologist Þor Þórðarson says the following regarding these events. (Summary: the secondary vents are just openings in the overpressured lava pond under Geldingadalir that continued to accumulated during the pause in surface activity)
“Hi all
Yesterday the eruption at Fagradalsfjall ones again put on a show as surface (visible) activity resumed after a 8.5 day-long pause. A visit to the eruption site yesterday late afternoon not only captured a good overview of this activity, but revealed several interesting features. However, first it is useful to point out that the eruption did not stop despite this 8.5 day pause in surface activity. It is evident that the opening that fed vent 5 clogged up, which prevented magma from entering the vent over this time period. This also halted formation of very large gas-bubbles, which explains the drop in tremor intensity. Yet, periodic but weak tremor episodes, steady outgassing from the vent, incandescent lava in skylights above lava tubes and newly scorched vegetation along the lava margins in Geldingadalir is a testimony that magma was streaming up through the conduit towards the surface during this 8.5 day-long pause in the surface activity.
This is further confirmed by the observations made during yesterday’s visit and below are the key points:
(i) The magma that was flowing yesterday into vent #5 did so through an opening at the base of the northwest crater rampart (Video 2021-09-12A) and later it also flowed out of openings higher up on the rampart, falling to the crater floor in impressive lava falls (Video 2021-09-12B).
(ii) At the same time the lava issued via sideways jet from a vent on the outside of the northwest rampart (Video 2021-09-12C) producing a few lava streams that flowed onto preexisting lava in Geldingadalir (Video 2021-09-12D) . This opening is clearly linked to the openings on the inner wall.
(iii) Lava was also spreading out in western part of Geldingadalir, but originated from several “secondary” vents (Videos 2021-09-12D and 2021-09-12E) that had opened up through the surface crust of the lava already residing in this part of Geldingadalir. Also, it is clear that the formation of this lava is not a direct consequence of the lava issuing from the opening at vent #5, because these new surface flows are distinct identities and clearly issuing from separate “vents” (Video 2021-09-12D). In other words, as is evident from the incandescent lava in the skylight and newly scorched vegetation in Geldingadalir, undegassed lava was flowing via internal pathways down into and accumulating in Geldingadalir during the pause in the surface activity. Apparently, yesterday the inner pressure in this ponded lava exceeded the strength of the overlying crust and lava began to bubbling up through the “secondary vents” (Video 2021-09-12E) and producing the surface flows that covered the western part of Geldingadalir. Perhaps, this activity can serve as an example of Areal eruptions mentioned by the German volcanologist Hans Reck around 1910?
Þorvaldur Þórðarson Eldfjallafræði og náttúrvárhópur Háskóli Íslands”
From https://www.facebook.com/Natturuva/posts/2992432440970843